¿Buscas esa expresión Xpath para extraer de webs el contenido de etiquetas HTML o algún dato concreto y se te resiste dar con la expresión que te permita hacerlo? Pues aquí vas a encontrar todo eso y mucho más.
No sólo voy a listar las expresiones Xpath más frecuentes si no que voy a darte otras que te resultarán de utilidad y pautas para que te cueste menos dar con alguna específica que necesites.
Qué son las expresiones Xpath y por qué este post
Las expresiones XPath -del inglés XML Path Language– sirven para identificar y extraer partes concretas de un contenido XML como pueda ser el etiquetado HTML de las páginas. Se basan en la jerarquía del HTML por nodos de modo que indicando la ruta concreta de un elemento podríamos sacar su contenido o atributos de éste.
El motivo por el que me he lanzado a hacer este post es doble, por un lado hay veces que uso expresiones Xpath «complejas» de forma repetitiva y me gustaría tener un sitio dónde las vaya recopilando todas para copiar y pegar y poder así ir mucho más rápido que teniendo que construirlas cada vez.
El segundo motivo es que comparto con frecuencia en Twitter, mi canal de Youtube o el de Webpositer contenido relacionado con escrapeo a través de Xpath y para el que no tengo tampoco recopiladas las expresiones que enseño, sobre todo en el caso de Twitter que van en Tweets aislados sin seguir un hilo ¡mea culpa, lo sé!
Esta es toda la «chapa» sobre XPath, vamos ya al grano.
Expresiones XPath con etiquetas HTML más habituales y parametrizadas
| Expresión XPath | ¿Qué nos devuelve? |
|---|---|
| //title | Contenido de la etiqueta title |
| //meta[@name=’description’]/@content | Contenido de la meta-etiqueta description |
| //h1 | Contenido de todas las etiquetas H1 que haya en la URL |
| //h1/text()[1] | Contenido de la primera etiqueta H1 que se encuentre |
| count(//h1) | Nº de etiquetas H1 en la página |
| //link[@rel=’canonical’]/@href | Valor de la etiqueta rel canonical |
| //meta[@name=’robots’]/@content | Valor de la etiqueta meta-robots |
| //a/@href[contains(.,’texto’)] | URL de un enlace que contengan en el valor de href el texto indicado, por ejemplo un dominio |
| //a[contains(@href, ‘texto’)] | Anchor text usado en un enlace que contenga el texto indicado en el atributo href |
| //a[contains(@href, ‘URL’)]/@rel | Valor de la etiqueta rel de un enlace (si existe) cuya URL coincida con la indicada |
| //a[contains(@rel, ‘nofollow’)]/@href | Relación de URLs de enlaces cuya etiqueta rel contiene nofollow |
| //a[@style=’display:none;’]/@href | Relación de enlaces ocultos con display:none; |
| //a[@href=’https://www.dominio.es/blog’]/attribute::* | Relación de atributos que tiene ese enlace |
| //link/@hreflang | Valores ISO de todos los hreflang definidos |
| //link[@hreflang]/@href | Valores (URLS) de los href que figuran en cada hreflang definido |
| //img[not(@alt)]/@src | Relación de imágenes sin texto en el atributo ALT |
| //*[@class=»breadcrumb»]/span/span/a | Todos los anchor texts de migas de pan para unas breadcrumbs que tienen el class «breadcrumb» (Ejemplo) |
| //meta[@name=»viewport»]/@content | Nos devuelve el contenido del viewport |
Esta ultima expresión relacionada con la extracción de elementos (anchor texts) de los distintos niveles de unas migas de pan es un ejemplo muy concreto sacado de un WordPress cuyas migas de pan tenían el class «breadcrumb» pero no es válido para cualquier WordPress ni para cualquier breadcrumbs. Extraer estos datos a veces puede ser bastante pesado sobre todo si al buscar la expresión XPath nos aparecen IDs de capas, el wrapper o incluso de posts. Para enteder la metodología mediante la que conseguir el XPath definitivo para tu análisis te comiendo que veas este vídeo de Xpath de mi canal y si te gusta… pues suscríbete. 🙂
XPath para escrapero de SERPs
| Expresión XPath | ¿Qué nos devuelve? |
|---|---|
| //*[@id=»rso»]/div/div/div[1]/a/@href | Relación de URLs del listado de la página de resultados |
| //*[@id=»rso»]/div/div/div[1]/a/h3 | Relación de titles de los snippets en el listado de la página de resultados |
| //*[@class=’card-section’]/div/p/a | Lista de búsquedas relacionadas que se muestra hacia el final de página de resultados |
| //*[@class=’related-question-pair’]/g-accordion-expander/div/div | Relación de preguntas+respuestas del bloque «Otras preguntas de los usuarios» |
| //div[contains(@data-sokoban-container,’i’)]/div[1]/div/a/@href | Relación de URLs del listado de la página de resultados – Actualizado a 25/11/2022 |
Estas 4 expresiones XPath son válidas en este momento pero Google suele cambiar con frecuencia la estructura de SERPs por lo que es probable que transcurrido cierto tiempo necesiten algún tipo de cambio o incluso sean totalmente diferentes.
XPath para escrapeo de Datos Estructurados, Twitter Cards y Open Graph
| Expresión XPath | ¿Qué nos devuelve? |
|---|---|
| //*[@itemtype]/@itemtype | Relación de todos los marcados de datos incluidos en la URL escrapeada |
| //meta[@property=’article:published_time’]/@content | Fechas de los posts, útil cuando el atributo fecha no se está visualizando en el post |
En esta última tabla podría incluir muchísimos más pero os dejo los únicos 2 que uso con cierta frecuencia, sobre todo el de las fechas.
Guía de uso de XPath
Para escrapear usando XPath solo necesitas 2 cosas, la expresión a escrapear y una herramienta de scraping como pueda ser la extensión Scraper para Google Chrome, Screaming Frog SEO Spider o el propio Google Sheets con su función IMPORTXML.
En el vídeo que mencionaba más arriba explico cómo obtener XPaths específicos pero te lo adelanto aquí también. En Chrome basta con que abras el inspector con F12 o con Botón derecho+Inspeccionar y sobre la línea de código de la que quieras obtener el XPath haces Click derecho > Copy > Copy Xpath.
Normalmente esa expresión XPath te valdrá para sacar un único elemento y en la mayoría de los casos querrás obtener listados o más valores por lo que te tocará hacer algunos ajustes sobre la expresión para poder aplicarlos después en alguna de esas herramientas. Te recomiendo que veas ese vídeo en el que pongo ejemplos de todo esto y enseño el método para que puedas dar con la expresión que necesitas.
En el vídeo incluyo solo ejemplos con Scraper y con IMPORTXML pero en este otro vídeo del canal de Webpositer pongo ejemplos de escrapeo con Screaming Frog.
Bonus XPath
- En este hilo de Twitter explico como usar XPath y la extensión de Chrome Scraper para obtener una relación de enlaces que no cumplen el patrón de terminación con o sin «/» final y para los que no se incluye anchor text o ALT, están en blanco.
- La extensión Scraper permite almacenar Presets de XPath para ir más rápido en tareas repetitivas, por ejemplo podemos guardar uno para para hacer scraping en formato tabla y pegar directamente en exel.
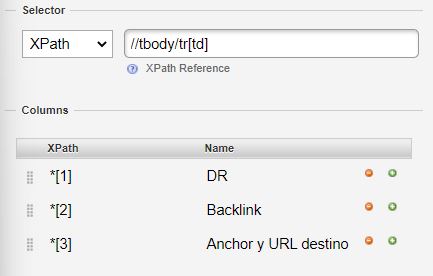
- La herramienta Ahrefs tiene una versión gratuita de su análisis de backlinks que no cuenta con opción de exportar y que NO podemos escrapear con Google Sheets u otras herramientas ya que los resultados se generan dinámicamente, pero con la que sí podemos usar la extensión de Chrome Scraper. La herramienta la tenéis aquí https://ahrefs.com/es/backlink-checker y estos son 2 presets que podéis usar para rapado de datos en modo tabla : /tbody/tr[td] o //tbody/tr/td/div[a] y //tbody/tr/td/div[p]
- Cheat Sheet de XPath : En este enlace encontraréis el listado de este blog en formato sheets para que podáis copiarlo.
- Masterclass XPath aplicado a SEO para ecommerce : Si quieres profundizar más sobre el uso de XPath en tu día a día como SEO y conocer incidencias y técnicas para ahorrar tiempo en la extracción de datos te recomiendo esta clase que hice para Quondos, además en esta comunidad de profesionales SEO encontrarás mucha más formación de alto nivel de otros consultores reconocidos a nivel nacional e internacional.
Ale pues hasta aquí el post sobre expresiones XPath para SEO, al menos de momento, las nuevas que vaya localizando y usando con frecuencia las iré incluyendo en actualizaciones de este artículo.
Como siempre espero que os sea de utilidad y si tenéis alguna duda o propuesta dejádmela en los comentarios.
¡¡Aaaaaaadios!!



2 respuestas
Miguel, muchas gracias por este listado de expresiones XPAth para SEO.
Con anterioridad ya había visto, pero no tenia ni idea de que trataba todo ello, pero con esta recopilación, ya la usaré de referencia para cuando este realizando escrapeo de los datos estructurados.
¿Se puede realizar el Scrapeo usando algún plugin de WordPress? He usado las herramientas que mencionas, pero me quede con esa duda.
Saludos!
Gracias por pasarte por los comentarios Ricardo! Me quiere sonar que hay algún plugin pero lo cierto es que nunca he necesitado nada parecido, de modo que no he probado ninguno, no te puedo recomendar nada 🙁