Aunque parezca curioso, este tema que a priori no debería entrañar ninguna dificultad, aún sigue generando dudas entre responsables y administradores de nuestra querida, a veces no tanto, plataforma de portal.
En este artículo voy a detallar dónde -narices- podemos encontrar el «fichero» robots.txt de nuestro portal y cómo configurarlo ya que visto lo que hay en SERPs (está en top10 todavía este post que me curré para la web de Liferay en 2009, casi nada!) creo que podrá resultar de ayuda y ahorro de tiempo.
AVISO POR ADELANTADO : En este artículo no voy a entrar en aspectos como para que sirve el robots.txt, la sintaxis y ese tipo de cosas de las que hay artículos a mansalva.
Ubicación y gestión del robots.txt en Liferay
Path del robots.txt ¿Dónde se encuentra?
Aunque sea de tipo «.txt» este fichero no se encuentra como tal, físicamente, en ningún directorio de la instalación para que lo podamos modificar, no es como el que podemos encontrar en una ruta concreta como la raíz del hosting de un WordPress.
Salvo que tengas una versión antiquísima de Liferay, y en este caso el robots.txt sería el menor de tus problemas, el robots.txt se genera dinámicamente desde la configuración de los sitios web.
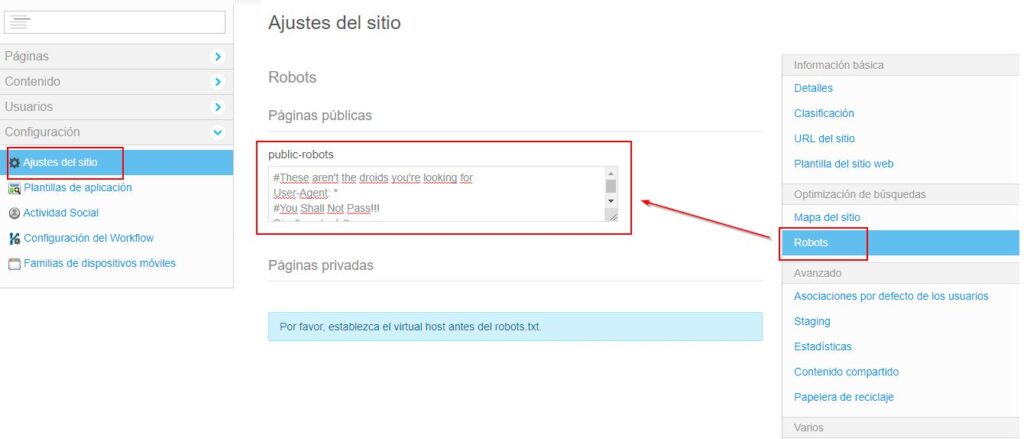
Liferay 6.2
Una vez que estemos en el panel de configuración del sitio web, podemos encontrar la configuración en:
Ajustes del sitio > bloque «Optimización de búsquedas» > Robots
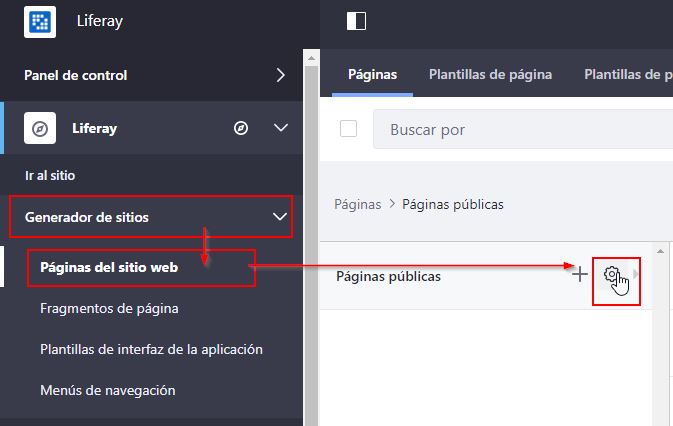
Liferay 7.2
En esta versión lo tenemos un poco más escondido. Primero habrá que acceder al apartado de configuración de páginas haciendo clic en :
Generador de sitios > Páginas del sitio web > Configurar (icono representado por una rueda dentada).
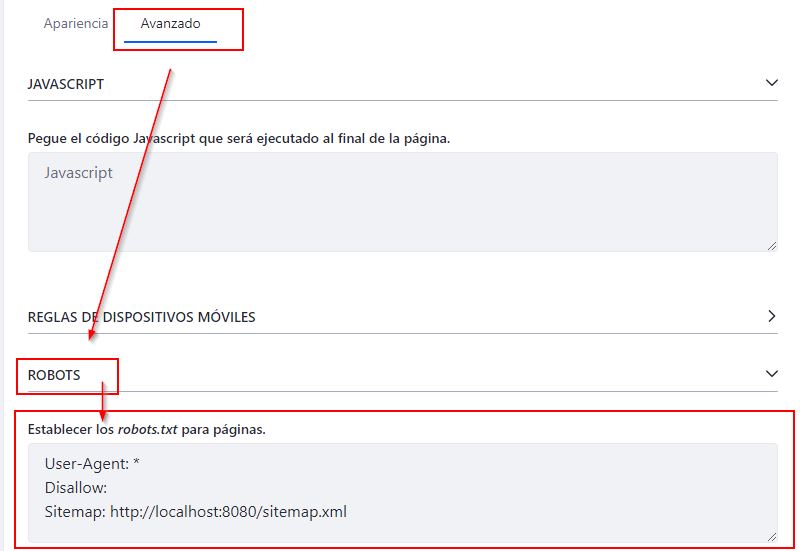
Hecho esto tendremos que hacer clic en la pestaña «Avanzado» y finalmente desplegar el apartado «ROBOTS» para poder añadir o eliminar las directivas que queramos.
¿Qué directivas son necesarias para Liferay?
Esta pregunta tiene más miga de la que parece porque nos podemos encontrar, y me encuentro, con muchísimos escenarios diferentes y dependerá mucho de qué gestión del rastreo necesite hacer el responsable SEO del portal.
Estas son algunas que suelo añadir con frecuencia ya que son patrones de URLs muy comunes en Liferay:
- Disallow: /*jsessionid=
- Disallow: /c/portal/login
- Disallow: /*create_account*
- Disallow: /*login?*
- Disallow: /c/portal/rate_entry
- Disallow: /*forgot_password*
Otras como p_p_auth= o p_p_id= pueden ser necesarias pero en algunos casos se podría llegar a bloquear el rastreo natural a muchas URLs de valor para el proyecto.
¿Es necesario bloquear /group/ para páginas privadas?
En algunas de las webs en las que se habla del Robots.txt para Liferay indican que debe ser bloqueado /group/ para evitar el rastreo de esas páginas pero si esto es necesario el problema podría ser en todo caso de indexación y permisos de páginas privadas ya que de partida ningún bot y ningún usuario debería poder llegar a las páginas privadas sin una identificación previa, si se intenta llegar a una el sistema de gestión de permisos hará un redirect 302 hacia la página de login.
En algún proyecto he sugerido añadir la directiva de disallow para group ya que en logs se detectaban eventos aparentemente maliciosos para ese patrón y otros patrones de URLs que seguro eran con no muy buenas intenciones, pero por defecto, como indico, no debería resultar un problema en una web que tenga sólo contenido público o páginas privadas no enlazadas públicamente. Además si un bot malicioso quiere acceder a cierto tipo de URLs ten por seguro que lo hará, intentes bloquearlo por robots.txt o no.
Si quieres saber si tienes páginas privadas indexadas puedes probar este comando en google:
site:tudominio.com inurl:group
Para terminar indicarte que tienes más información sobre optimizaciones de robots.txt, el meta-robots y la etiqueta X-Robot-Tag en mi curso de SEO para Liferay.
Como siempre…¡Espero que te haya sido de utilidad! ¡Saludoooos!



2 respuestas
Excelente, muy práctico, directo al grano
¡Hombre Randall! ¡Cuánto tiempo! Me alegra verte por aquí y saber que te ha gustado el post. Recuerdos a tus compañeras.